The national service for operating large language models, run by CERIT-SC under e-INFRA CZ, has reached a significant milestone. Since its launch, it has served more than 1,700 users from the Czech academic and research community and processed over 100 billion tokens. The service confirms its role as a key piece of national infrastructure for working with modern language models in an environment that respects data sovereignty requirements.
Powerful Hardware Backbone
The service is powered primarily by two NVIDIA DGX systems—the B200 model with 1.4 TB of GPU memory and the more powerful B300 with 2.1 TB of GPU memory. This setup makes it possible to simultaneously run several state-of-the-art open language models at production quality, including variants that typically require premium tiers from commercial providers.
The current model lineup includes:
- Qwen 3.5—a reliable model well-suited for programming tasks, reaching peak throughput of over 2,000 tokens per second
- Kimi K2.6—deployed in "0-day" mode on the day of its official release
- DeepSeek V3.2—running on eight B200 GPUs, soon to be replaced by version V4 Pro
- GLM 5.1—a model in NVFP4 quantization, popular especially for more demanding agentic tasks
- And lighter models such as Qwen3.5-122B, GPT-OSS-120B, or Mistral Small 4 for conversational scenarios, running on mid-range GPUs.
What's Behind the 100 Billion Tokens
The vast majority of processed tokens are inputs—user prompts, conversation context, and the contents of files that models read during processing. The ratio of input to output tokens for agentic models reaches values of 17 to 18 to one. This trend is primarily fueled by modern agentic tools like Claude Code. By re-sending the entire conversation history, tool definitions, and active file contents with every turn, a single morning of coding can easily burn through millions of tokens before lunch.
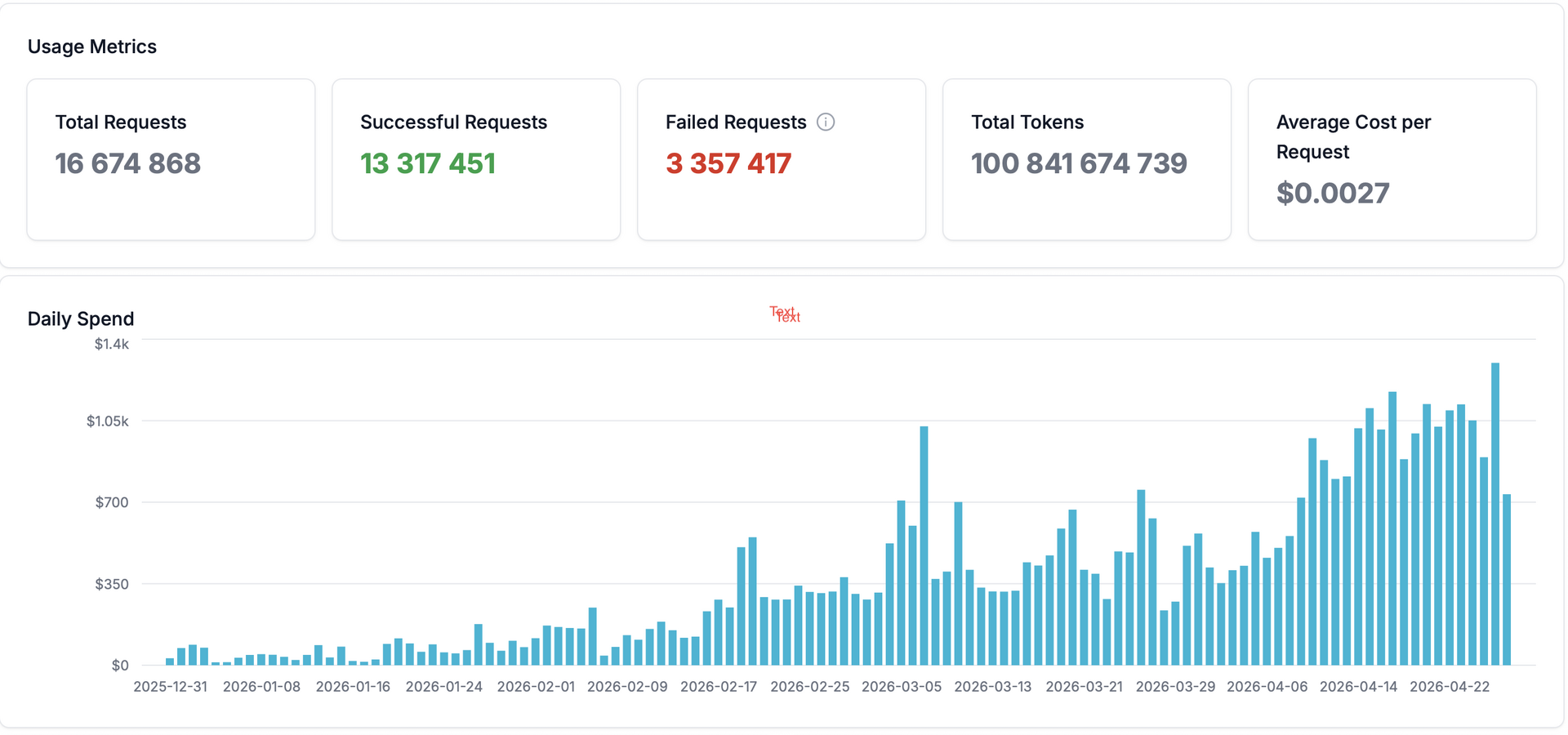
Last month's statistics illustrate the contrast between typical and most demanding usage strikingly—the median prompt length for Kimi K2.6 is around 2,200 tokens, while the 95th percentile reaches nearly 100,000 tokens per single request.
Economics That Make Sense
Let's break down the calculation. The acquisition cost of the two DGX systems is approximately 1 million USD. Factoring in 20% operational overhead (energy, cooling, staffing) and a three-year lifespan, the monthly hardware cost comes to roughly 33,300 USD.
If we were to value the processed tokens at the rates of Chinese providers—that is, the price at which the same open models would be available in their country of origin—last month's traffic volume would correspond to approximately 25,800 USD. From this perspective, it might appear that e-INFRA CZ is losing about 7,500 USD per month on running the service, since the hardware costs more than the equivalent price for the inference itself. The question naturally arises whether running it in-house is even worth it.
The reality, however, is different—models hosted in China cannot be legally used by institutions and for sensitive tasks in line with NÚKIB recommendations. The real alternative is therefore the Western commercial market—Anthropic, OpenAI, and similar providers—at premium rates. And once we value the same monthly traffic at rates comparable to Anthropic Sonnet, we arrive at approximately 137,900 USD per month.
The original "loss" of 7,500 USD suddenly turns into savings of more than 104,000 USD per month. Over a year, that amounts to roughly 1.25 million USD—which, coincidentally, almost exactly matches the acquisition cost of both DGX systems, including overhead. Users of e-INFRA CZ thus save institutions an amount equivalent to the entire hardware backbone of the service every year—while maintaining full control over their data.
Data Stays at Home
The key added value of the national service is data sovereignty. The National Cyber and Information Security Agency (NÚKIB) restricts the use of models hosted in China for institutions and sensitive tasks. Open models of Chinese origin, such as Kimi, GLM, or DeepSeek, are nevertheless operated directly on hardware located in the Czech Republic, under Czech jurisdiction, and no user data leaves the e-INFRA CZ infrastructure. The service thus delivers exactly the arrangement the regulation anticipates—modern AI tools available to the research community without compromising data security.
Open Call: Bring Your Own Hardware
CERIT-SC invites research groups and institutions that have suitable GPU equipment to join the national LLM infrastructure. The minimum technical requirement is at least 4 NVIDIA H100-class or newer GPUs with native FP8 support and aggregate memory of 500 GB, matching the hardware demands of modern open models. Connected nodes can benefit from a dedicated allocation for their own research while also contributing free capacity to the shared pool.
What's Next
The CERIT-SC team is planning the upcoming deployment of the DeepSeek V4 Pro model and the ongoing expansion of the portfolio with new open models as they appear. The goal remains the same: to provide the Czech research community with access to the most advanced language models in a performant, economically sustainable environment that fully respects data sovereignty requirements.
For more technical details on the service's operation and the deployed models, see Lukáš Hejtmánek's in-depth blog post on the e-INFRA CZ Blog, "100 Billion Tokens."
