Národní služba pro provoz velkých jazykových modelů, kterou v rámci e‑INFRA CZ provozuje CERIT‑SC, dosáhla významného milníku. Od svého spuštění obsloužila více než 1 700 uživatelů z české akademické a výzkumné komunity a zpracovala přes 100 miliard tokenů. Služba tak potvrzuje svou roli klíčové národní infrastruktury pro práci s moderními jazykovými modely v prostředí, které respektuje požadavky na datovou suverenitu.
Výkonné hardwarové zázemí
Provoz služby zajišťují především dva systémy NVIDIA DGX — model B200 s 1,4 TB paměti GPU a výkonnější B300 s 2,1 TB paměti GPU. Tato sestava umožňuje současně provozovat několik nejmodernějších otevřených jazykových modelů v produkční kvalitě, včetně variant, které u běžných poskytovatelů vyžadují prémiové tarify.
V současné nabídce služby najdou uživatelé:
- Qwen 3.5 — spolehlivý model vhodný mimo jiné pro programátorské úlohy, dosahující špičkové propustnosti přes 2 000 tokenů za sekundu,
- Kimi K2.6 — nasazený v tzv. 0‑day režimu už v den oficiálního vydání,
- DeepSeek V3.2 — provozovaný na osmi GPU B200, brzy nahrazený verzí V4 Pro,
- GLM 5.1 — model v kvantizaci NVFP4 oblíbený zejména pro náročnější agentické úlohy
- a další lehčí modely jako Qwen3.5‑122B, GPT‑OSS‑120B nebo Mistral Small 4, které běží i na menších GPU akcelerátorech.
Co stojí za 100 miliardami tokenů
Drtivou většinu zpracovaných tokenů tvoří vstupy — uživatelské prompty, kontext konverzace a obsah souborů, které modely při zpracování čtou. Poměr vstupních a výstupních tokenů u agentních modelů dosahuje hodnoty 17 až 18 ku jedné. Za tímto trendem stojí především moderní agentní nástroje typu Claude Code a podobné, které při každém kroku znovu odesílají kompletní historii konverzace, definice nástrojů i obsah pracovních souborů. Jedna ranní programátorská session tak může v klidu do oběda spotřebovat několik milionů tokenů.
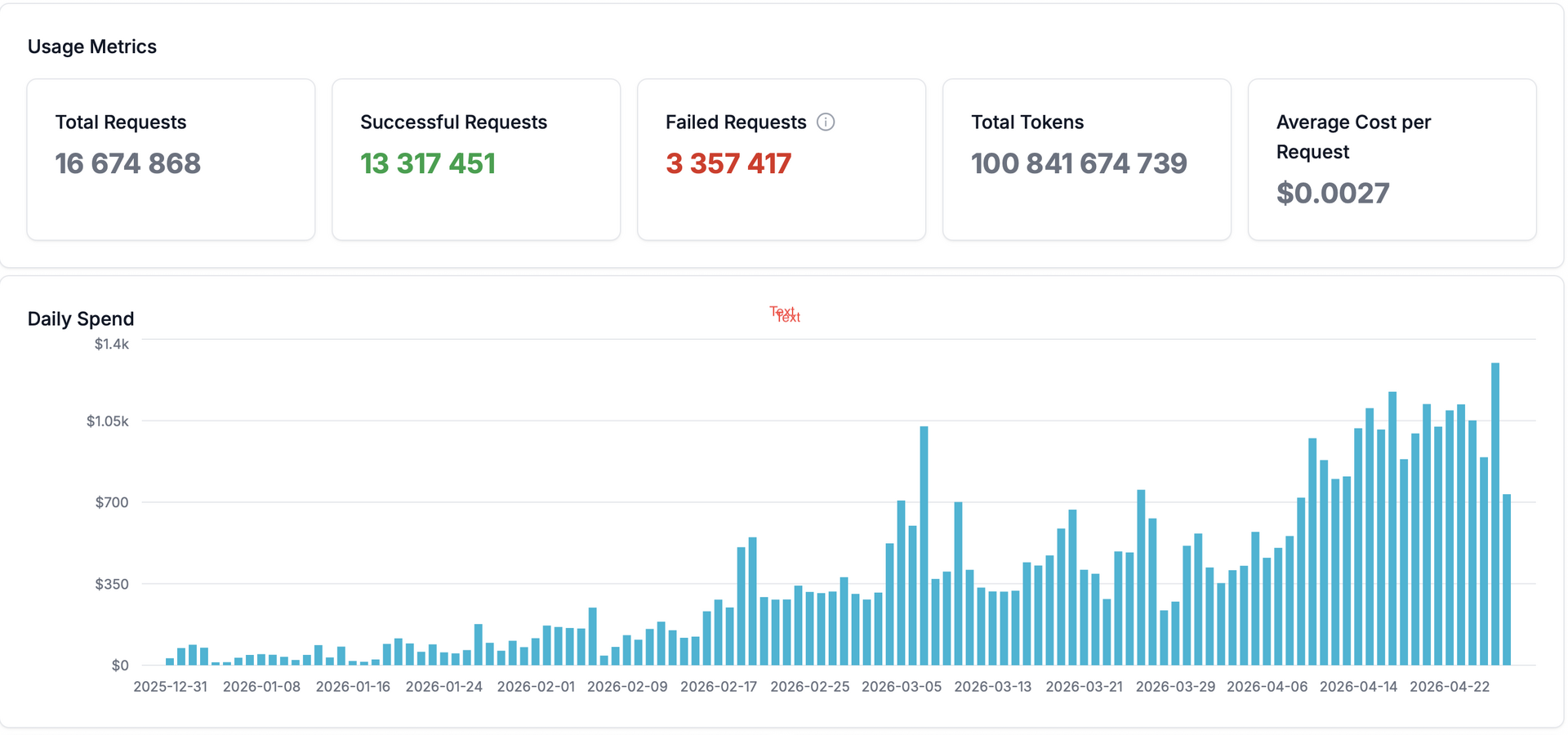
Statistiky z posledního měsíce ukazují kontrast mezi typickým a nejnáročnějším použitím výmluvně — medián délky promptu se u Kimi K2.6 pohybuje kolem 2 200 tokenů, zatímco 95. percentil dosahuje téměř 100 000 tokenů na jeden požadavek.
Ekonomika, která dává smysl
Pojďme si propočet rozepsat. Pořizovací cena dvou systémů DGX činí přibližně 1 milion USD. Při započtení 20 % provozní režie (energie, chlazení, lidská práce) a životnosti tří let vychází měsíční náklad na hardware na zhruba 33 300 USD.
Pokud bychom zpracované tokeny ocenili sazbami čínských poskytovatelů — tedy cenou, za kterou by tytéž otevřené modely byly k dispozici v zemi svého původu — odpovídal by objem provozu za poslední měsíc přibližně 25 800 USD. Z tohoto pohledu se může zdát, že e‑INFRA CZ na provoz služby každý měsíc doplácí zhruba 7 500 USD, protože hardware stojí víc, než kolik by činila ekvivalentní cena za samotnou inferenci. Nabízí se otázka, zda se vlastní provoz vůbec vyplatí.
Realita je ovšem jiná — modely hostované v Číně nejsou pro instituce a citlivé úlohy v souladu s doporučením NÚKIB legálně použitelné. Skutečnou alternativou je tedy západní komerční trh — Anthropic, OpenAI a podobní poskytovatelé — za prémiové sazby. A v okamžiku, kdy stejný měsíční provoz oceníme sazbami srovnatelnými s Anthropic Sonnet, dostáváme se na přibližně 137 900 USD měsíčně.
Z původního „doplatku“ 7 500 USD se rázem stává úspora přes 104 000 USD měsíčně. Za rok to dělá zhruba 1,25 milionu USD — což je, shodou okolností, téměř přesně částka odpovídající pořizovací ceně obou DGX systémů včetně režie. Uživatelé e-INFRA CZ tedy každý rok ušetří institucím prostředky odpovídající celému hardwarovému zázemí služby — a to při zachování plné kontroly nad daty.
Data zůstávají doma
Klíčovou přidanou hodnotou národní služby je datová suverenita. Národní úřad pro kybernetickou a informační bezpečnost (NÚKIB) omezuje pro instituce a citlivé úlohy využívání modelů hostovaných v Číně. Otevřené modely čínského původu, jako jsou Kimi, GLM nebo DeepSeek, jsou ovšem provozovány přímo na hardwaru v České republice, pod českou jurisdikcí, a žádná uživatelská data neopouštějí infrastrukturu e‑INFRA CZ. Služba tak naplňuje přesně to uspořádání, které regulace předpokládá — moderní AI nástroje dostupné výzkumné komunitě bez kompromisu v oblasti bezpečnosti dat.
Otevřená výzva: přineste vlastní hardware
CERIT‑SC zve výzkumné skupiny a instituce, které disponují vhodným GPU vybavením, aby se k národní LLM infrastruktuře připojily. Minimální technický požadavek představují alespoň čtyři GPU třídy NVIDIA H100 nebo novější s nativní podporou FP8 a souhrnnou pamětí v řádu 500 GB, což odpovídá hardwarovým nárokům moderních otevřených modelů. Připojené uzly mohou těžit z dedikované alokace pro vlastní výzkum a zároveň přispívat volnou kapacitou do sdíleného fondu.
Co bude dál
Tým CERIT‑SC plánuje v nejbližší době nasazení modelu DeepSeek V4 Pro a průběžné rozšiřování portfolia o nové otevřené modely, jakmile se objeví. Cíl zůstává stejný: poskytovat české výzkumné komunitě přístup k nejmodernějším jazykovým modelům v prostředí, které je výkonné, ekonomicky udržitelné a plně respektuje požadavky na datovou suverenitu.
Více technických detailů o provozu služby, nasazených modelech najdete v podrobném blogovém příspěvku Lukáše Hejtmánka na e‑INFRA CZ Blogu „100 Billion Tokens“.
